202403.GAT_AMD:基于图注意力网络和多模态特征深度融合的Android恶意软件检测方法 Android malware detection method based on graph attention networks and deep fusion of multimodal features(精读)
这是提炼后的笔记↓

总结用了什么模块
- 数据预处理(apktool、JADX、LibRadar)
- 构建类集调用图(CSCG)
- 主题模型(TD-IDF、LSI):对调用图节点使用主题模型提取代码语义特征
- Max_GAT:
- 深度特征融合网络:融合两种特征并分类
对调用图的生成大小有一个自适应调节的机制存在,让调用图的的大小尽量控制在一个区间内,即避免图过大导致计算开销巨大,又避免图过小导致信息过少
- 本文是采用了很多模块组合构成的一个大的恶意软件检测系统
动机
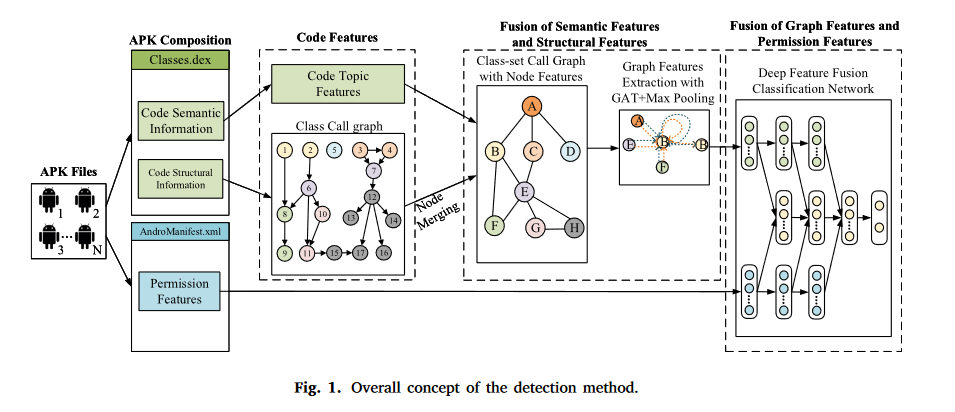
安卓恶意软件检测中常见特征包括xml文件中的权限特征和dex文件中的语义和结构特征。恶意软件检测的关键就是如何从这些文件中提取出有效的多维度特征。
作者在2019年提出过一种主题模型(topic model),可以有效地提取代码的语义特征。这篇文章在这个模型上继续发展,19年的方法是从apk中提取全局的主题向量,但是恶意软件的恶意行为通常发生在特定的代码区域,全局特征不能准确的表示区域特征。
因此本文构建了一个调用图,图节点对于程序代码的特定单元,并提取节点的主题向量作为节点特征。然后使用GAT模型来提取显著区域特征作为整个图的特征,从而融合节点特征和结构信息
本文的调用图:
- 传统调用图每个节点代表一个函数,但是java的函数可能包含的单词太少从而无法提取到有效的主题特征。因此本文选择使用每个类作为一个节点,进一步将一些类节点合并为类集节点并构建类集调用图(CSCG)。这个方法增强了每个节点的语义信息,并减少调用图的规模
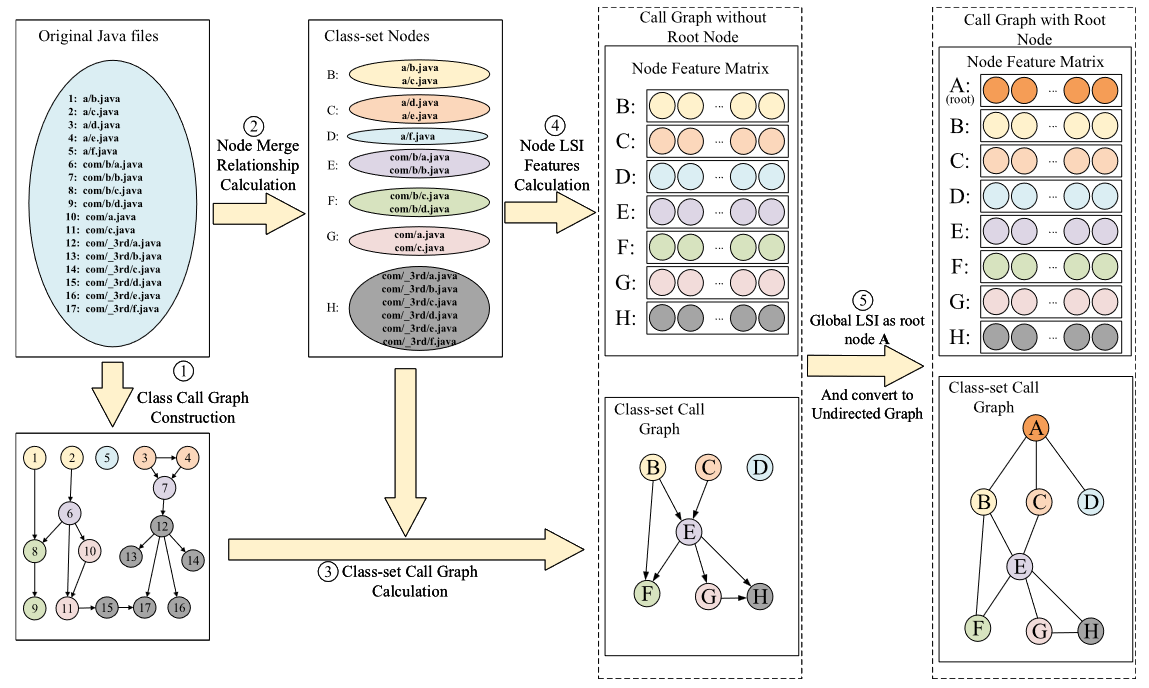
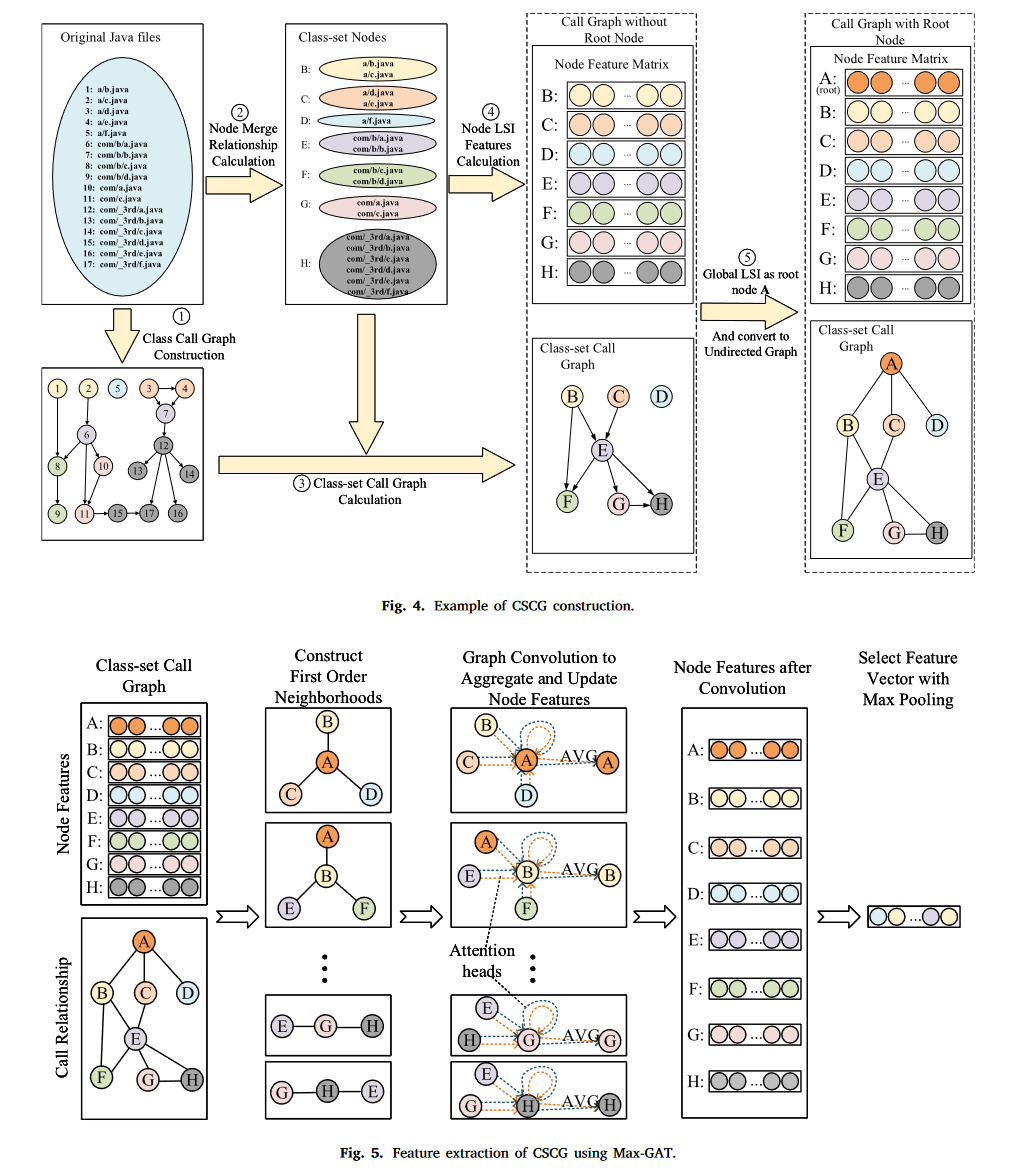
- 例如图中,代码包含17个java文件,进行处理后可以归档成一个8个节点的CSCG
CSCG图特征 和 权限特征 这两个特征的差异很大并且相关性也很低。本文使用深度特征融合网络(三层神经网络)来融合这两种特征并二分类
方法介绍
技术框架
数据预处理:
- 使用LibRadar检测apk包含的第三方库
- apktool对apk提取出xml、dex文件
- 使用JADX对dex反编译得到java源代码
- 根据文章:StursDroid 给出的59个高危权限从xml中提取权限特征
主题模型训练
- 源代码处理:从java源代码中删除检测到的第三方库代码,得到精简代码
- 构建训练数据集:使用java词法分析器对源代码进行分段,保留标识符、字符串和数字
- 训练TD-IDF模型:根据训练数据集训练得到TF-IDF特征向量
- 训练LSI(潜在语义索引)模型:训练模型并计算全局LSI特征向量
CSCG构建:
- 构建一个类调用图:对每个apk文件,使用Java源代码的公共类构建的类调用图
- 节点合并:根据Java包结构和第三方库检测结果对节点(类)进行合并,这里每个新节点代表一个类集
- 建立节点特征:计算每个类集的LSI向量以建立节点特征
图特征提取和多特征融合
- 图特征提取:使用带有最大池化层的GAT从CSCG中提取显著区域特征作为图特征,其中涉及语义模态和结构模态的特征融合
- 三层神经网络对所有特征进行二分类
GAT_AMD 方法再总结
- 使用apktool提取出dex和xml文件
- 从xml文件提取**权限特征
- jadx反编译dex文件获取java源码
- 使用LibRadar检测记录代码中的第三方库
- 删除第三方库用于主题向量构建
- 对剩余代码使用Java词法分析器进行词法分析
- 对源代码分段
- 记录所有单词出现的次数,构建单词字典
- 主题模型
- 根据字典用TF-IDF模型提取TF-IDF向量(重要词语向量)
- 潜在语义索引LSI对TF-IDF向量进一步提取主题向量(LSI特征向量)
- CSCG类集调用图(创新点)
- 根据java源码构建类调用图
- 图节点合并
- 计算节点主题向量作为图中的节点特征
- Max-GAT网络提取CSCG特征向量(创新点)
- 节点特征:节点LSI向量+主题模型LSI特征向量,
- 边特征:节点调用关系
- 三层BP神经网络做分类(创新点)
- 特征向量:权限特征向量、CSCG特征向量
CSCG构建
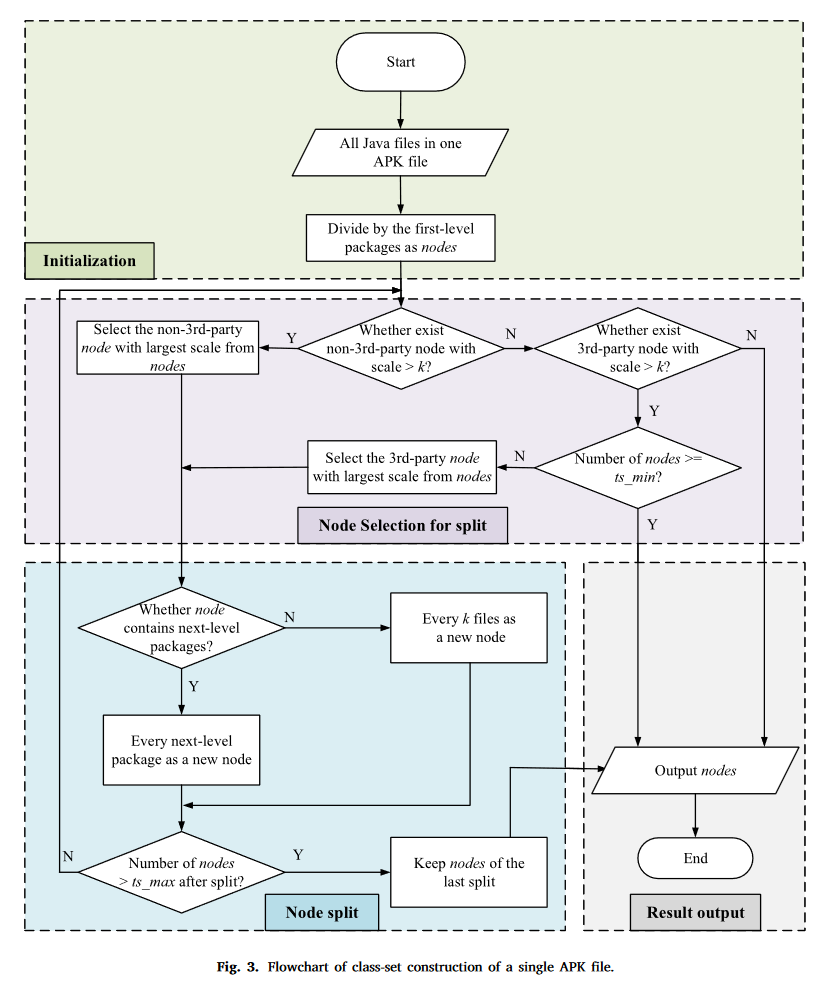
本节介绍:构建方法概述、节点合并方法、合并方法中的自适应节点大小计算。展示节点特征提取和边构建方法。最后举了一个例子
概述
每个类相当于是一个Java文件,被视为一个节点。为了增强节点中的语义信息并控制图的规模,在构造类集调用图的时候设置节点数量上限ts_max和下限tx_min
第三方库可能会干扰主题向量的代表性,但是第三方库中也有很小的概率包含恶意行为,完全删除第三方库可能导致调用关系不完整,因此为减小第三方库节点的比例,在合并节点的时候会尝试将每个第三方库合并为一个类集节点,并将非第三方库分离成尽可能多的类集节点。
意思就是当第三方文件数量达到ts_min时,将每个第三方库直接合并为一个类集节点,当第三方文件数量不足的时候,可以适当分离第三方库节点。
这么操作就减少了第三方库的节点比例,减少了第三方库的影响
根据ts_max、tx_min和第三方库检测结果计算每个apk文件的节点尺寸k,确保所有非第三方类集节点包含大致等量的信息。由于apk文件规模差异很大,过大的apk可能会导致规模和结构的信息丢失,这里设计了一种自适应算法来自动计算特定apk的节点尺寸k,算法对apk文件的类调用图按比例所见,从而有效保留结构和大小信息
获得合并的类集节点以后,计算节点特征的主题向量,然后将基本类调用图之间的调用关系作为边映射到CSCG
类集调用图建立的例子

类集调用图构建一共5个步骤:
- 计算Java文件之间的调用关系,得到基本类调用图
- 计算java文件之间的合并关系,根据自适应算法计算出
k值[1],这里计算出的是2,也就是普通节点中最多包含k个文件。然后进行节点合并,得到7个类集节点(B-H),类集节点中,H包含第三方库中的全部6个文件,其他节点最多包含k个文件 - 根据合并后的类集节点计算调用关系
- 利用Java词法分析器[2]对17个类进行分词,得到每个节点对于的单词,然后计算7个节点的LSI向量
- 添加全局LSI特征作为根节点
A,由于BCD没有被调用,这里添加A到BCD的边,然后将调用图转换为无向图作为最终的CSCG
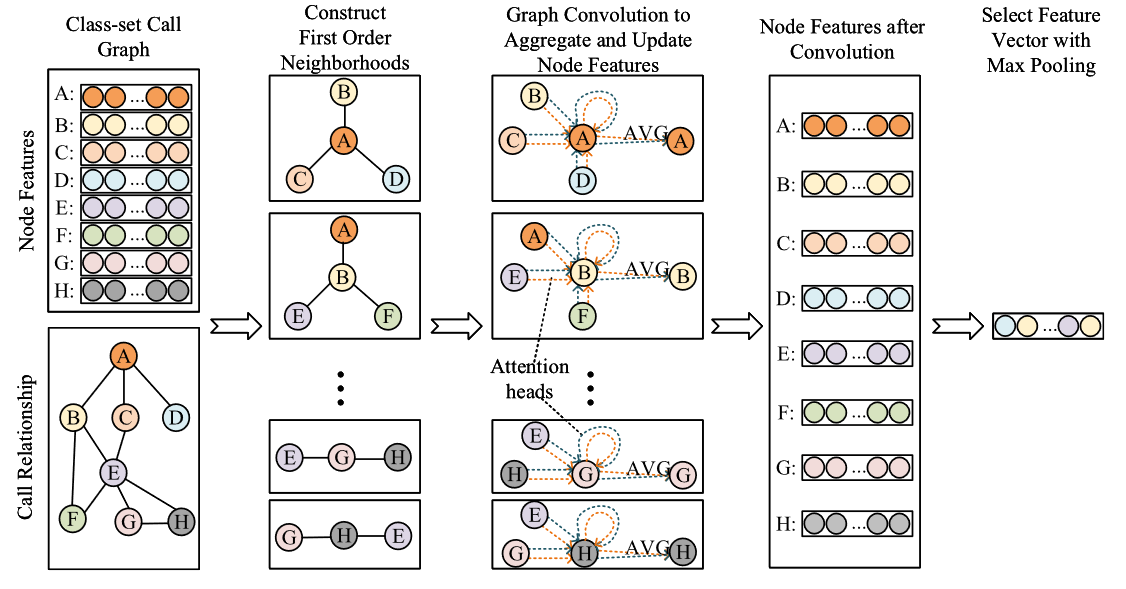
图特征提取
本文提出最大池化层结合GAT模型的名为Max-GAT的网络。Max-GAT基于GAT获得的所有节点特征,通过最大池化从每个维度提取最大数量的特征,并将结果作为CSCG特征。
图中,每个CSCG表示为 n*n 邻接矩阵和 n*500 节点特征矩阵,其中500是特征维度,n是节点数量。
- 首先,根据调用关系,识别每个节点的一阶邻居,并使用GAT构建多头注意力机制,通过应用多个独立的注意力机制来增加模型的容量。在图5中,注意力头的数量用从一个相邻节点到每个中心节点的箭头数量表示,并作为一个重要参数进行调整。
- 对于每个注意力头,首先对所有节点特征进行变换,然后对于每个节点,使用相邻节点特征的加权平均来获得更新的特征。将多头图卷积得到的特征的平均值作为最终特征。然后得到
n*128的特征矩阵,通过最大池化,选择最大特征向量(128维)作为全图的特征向量。
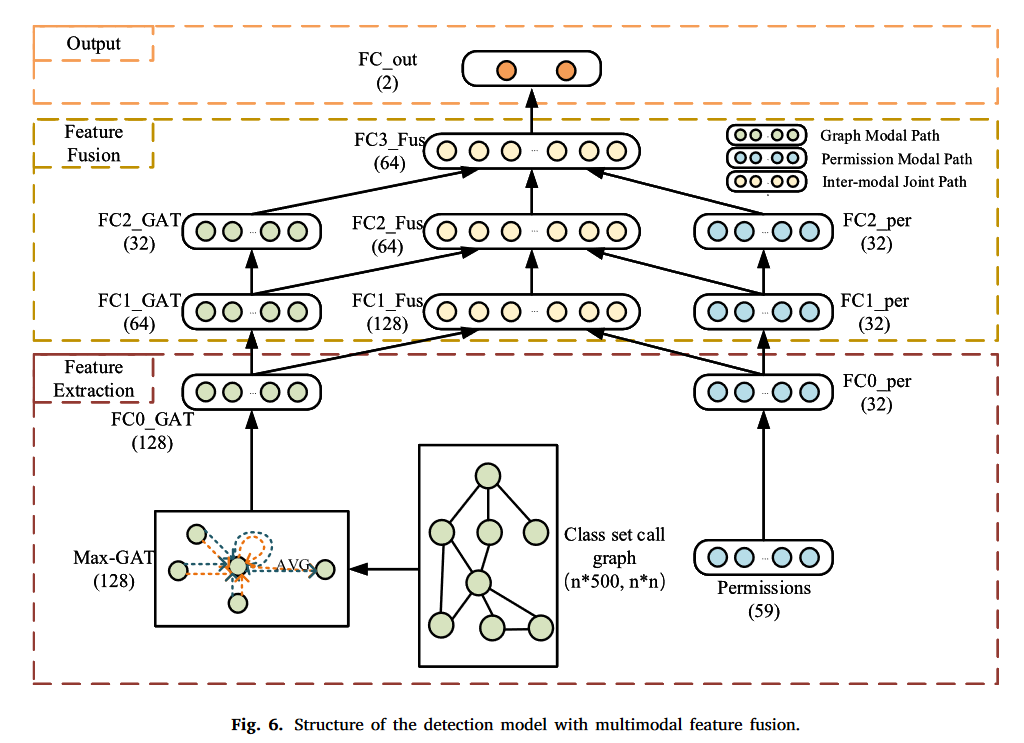
多模态特征融合and二分类
为了融合图模态和权限模态特征,本文设计了一个多层神经网络。
每层的大小(输出特征维度)在括号中表示。
对于APK文件,首先获取CSCG,然后计算初始128维图模态特征向量(Max_GAT)。
选择59维权限特征向量作为初始权限模态特征向量。两个模态特征之间的尺寸差异不利于特征融合。因此,为每个模态特征引入全连接层以减少这些差异。
然后,构建一个三层神经网络,每层作为融合点,并从 Fc3_Fus 获得 64 维融合特征。通过最终的全连接层 FC_out 得到最终的二分类结果。

时间复杂度分析
这里又相当于是代码的介绍
翻译正文↓
本文作者的上一篇文章:主题模型:
摘要:
目前,Android恶意软件检测方法始终专注于一种应用程序特征,例如结构、语义或其他统计特征。本文提出了一种新颖的 Android 恶意软件检测方法,该方法集成了 Android 应用程序的多种功能。首先,为了有效地提取结构和语义特征,我们提出了一种名为类集调用图(CSCG) 的新型调用图,它使用Java类的集合作为节点,类集之间的调用关系作为边,并且我们设计一种动态自适应CSCG构建方法,可以自动确定不同规模应用的节点大小。主题模型用于从类集中挖掘源代码语义作为节点特征。然后,我们使用具有最大池化的图注意力网络(GAT)来提取包含 Android 应用程序的语义和结构特征的 CSCG 特征。此外,我们构建了一个深度多模态特征融合网络,将 CSCG 特征与权限特征融合。实验结果表明,我们的方法在三个构建的数据集上实现了 97.28%–99.54% 的检测准确率,优于现有方法。
1. 介绍
Android系统于2008年首次推出,2021年搭载Android系统的智能手机数量突破30亿部。2015年7月,Google Play商店中的Android应用程序总数超过160万个,超过了2015年Android应用程序的总数量。 iOS 应用商店。随着应用程序数量的增加,Android恶意软件的数量也迅速增加。根据360移动安全报告(360安全中心,2022),2021年新发现的Android恶意软件数量达到940万个。因此,对Android恶意软件检测方法的研究就显得尤为重要。
目前,Android应用程序的主要安装文件格式是APK(Android应用程序包)。尽管谷歌在2018年启用了新的文件格式AAB(Android APP Bundles)(Beebom Staff,2021),但AAB格式仅是为开发者上传应用程序而设计的,而用户下载的安装文件仍然是APK格式。因此,本文重点研究APK格式文件的恶意软件检测。
根据特征提取中是否需要执行应用程序,不同平台(例如Windows和Android)上的恶意软件检测方法可以分为3类,即静态方法、动态方法和混合方法(Odusami等人,2018)邱等人,2020)。对于Android恶意软件检测,静态方法从反编译获得的源代码中提取特征。动态方法通过在实际或模拟环境中运行APK文件来提取特征,然后获得相应的行为模式。混合方法集成静态和动态特征来描述应用程序的各个方面。总体而言,动态方法通常提供较高的检测精度并保证对未知恶意软件的检测能力。然而,检测过程很复杂并且需要大量的计算资源。此外,动态方法通常无法遍历应用程序的所有可能的执行路径,这可能会导致报告丢失。静态方法不需要运行应用程序,检测效率高,可有效用于大规模Android应用程序检测。因此,本文重点研究一种新的静态检测方法。
静态方法主要有三类:图方法,表示APK文件各组成部分之间的关系,基于图结构实现检测;基于语义特征的方法,提取APK代码的语义特征;基于特征工程的方法,提取APK代码的语义特征。使用权限、意图和其他统计特征。对于基于图的方法,Gao、Cheng 和Zhang (2021) 以及 Hei 等人。 (2021)构建了一种同构信息网络(HIN)来表示一个数据集中的应用程序及其组件(例如 API 和权限)之间的关系。然后,应用程序之间的关系用于检测恶意软件。大多数图方法提取APK文件的结构特征并使用该特征进行检测。这种方法构建控制流图(CFG)或函数调用图(FCG)(Allix, Bissyandé, Jérome et al., 2016; Xu, Ren,qin, & Craciun, 2018; Xu, Ren, & Song, 2019)等,基于Java函数或类等内部代码区域的关系,利用图卷积网络等模型来获取结构特征并实现分类。由于恶意软件的恶意行为通常包含在特定的代码区域(即图节点)中,因此在检测中融合代码的语义特征非常重要。然而,现有的图方法没有考虑节点的语义特征。一些图方法使用的节点特征是统计特征而不是代码语义特征(Vinayaka & Jaidhar,2021;Xu 等人,2017)。 Milosevic、Dehghantanha 和 Choo(2017)以及我们小组在之前的工作(Song、Chen、Lang、Liu 和 Chen,2019)中证明了代码的语义特征可以很好地反映 Android 恶意软件的恶意行为。然而,这些方法只关注语义特征,而没有考虑结构信息。
为了解决这些问题,本文提出了一种结合代码的结构特征、语义特征和权限特征的方法。首先,我们基于 APK 文件的 Java 包结构构建一个类集调用图(CSCG)。类集代表代码区域,从代码区域提取的主题向量代表语义信息,并成为节点的特征。然后,我们使用带有最大池化的 GAT 来提取 CSCG 特征,它融合了显著区域的语义特征和 APK 文件的结构信息。最后,CSCG 特征和权限特征通过特征融合网络进行融合。
在CSCG的构建中,许多Java函数包含很少的单词(可能只有1个return语句),导致主题向量高度随机。因此,我们首先用Java源代码中的类而不是FCG构建一个调用图,称为类调用图。由于Java代码中的每个类通常都与一个独立的文件相关联,因此这里的一个类就等于一个Java文件。与FCG相比,类调用图可以有效增加一个节点存储的信息。同时,我们注意到许多应用程序都有大量的类被组织到 Java 包中。在 Java 语言中,单个包中的类具有相似的语义(Arnold、Gosling 和 Holmes,2005)。因此,为了增强每个节点的语义信息,我们提出了一种自适应类合并算法来构造使用Java类集作为节点的类集调用图(CSCG)。 CSCG还可以大大减少节点数量,从而减少调用图的计算负载。
CSCG的规模与APK文件的规模和计算资源有关。为了有效控制CSCG的规模并确保保留原始调用图中更多的信息,我们还设置了节点数量的上限和下限。第三方库的代码一般存在于Android源码中;这些代码通常是提供特定功能的现成实现的通用代码。这些特征可能会对恶意软件检测构成噪声(Aafer,Du,&Yin,2013;Song等,2019;Zhan等,2020),从而影响检测效果。然而,第三方库中的代码也可能包含恶意行为(Li et al., 2017),因此我们不能直接删除第三方库。为了减少第三方库的影响,我们优先合并第三方库中的类,以减少CSCG中第三方库节点的比例。此外,调用图的规模是一个重要的信息。我们在构建CSCG时采用比例缩减来保留类调用图之间的尺度差异。
综上所述,本文的贡献如下:
- 论文提出了一种用于Android恶意软件检测的多模态深度特征融合方法。我们设计了一种新型的调用图(即类集调用图),它将结构信息与相应代码中潜在主题的语义特征相结合,并构建了一个深度融合网络来结合图特征和权限特征。该方法在三个开放的 Android 恶意软件数据集上实现了 97.28%–99.54% 的检测准确率,高于最先进的方法。
- 提出了一种具有自适应节点大小的类集调用图(CSCG)构造方法。该方法采用比例约简的概念动态计算单个图节点中的类数量,并基于Java类的树状封装结构设计了自上而下的迭代类合并算法。因此,构建的调用图可以丰富源代码的语义信息,并减少调用图的规模,从而减少计算负荷。
- 使用主题模型从源代码中提取语义特征,并引入带有最大池化的GAT来提取CSCG的特征。此外,还提出了深度特征融合网络,实现图特征和权限特征的有效融合。
在本文的其余部分安排如下。第 2 节介绍了 Android 恶意软件检测的相关工作。第三节介绍了研究动机和基于图注意力网络、主题模型和深度融合网络的检测框架。第4节展示了应用数据集的构建以及基于这些数据集的模型的实验结果;然后,我们的方法与其他最先进的方法进行比较。第 5 节总结了本文。
2. 相关工作(介绍别人的方法)
Android恶意软件检测方法从特征来源的角度可以分为静态方法、动态方法和混合方法。静态方法无需运行 APK 文件即可提取特征并执行分类。
- 许多静态方法通过特征工程提取特征,并使用机器学习或深度学习模型进行分类。
- 另一种方法是提取语义特征,从源代码中挖掘语义信息进行检测。
- 此外,一些方法使用图方法来提取应用程序的结构特征或分析不同应用程序之间的关联性。
- 动态方法通过在实际或模拟环境中运行 APK 文件来提取特征。混合方法集成静态和动态特征来描述应用程序的各个方面。
所提出的方法是静态方法,因此,在本节中,我们主要关注相关工作中应用的静态检测方法。我们的方法是基于图模型的,因此我们将静态方法分为基于特征工程和语义特征的方法和基于图模型的方法。
2.1.基于特征工程和语义特征的静态方法
大多数静态方法解压APK文件以获得特定文件,包括“AndroidManifest.xml”和“classes.dex”,然后从中提取相应的特征。其中,“AndroidManifest.xml”文件用于配置一些重要信息,如包名、权限、程序组件等。
权限等功能(Milosevic et al., 2017;Şahin, Kural, Akleylek, & Kılıç, 2021;Talha, Alper, & Aydin, 2015;Yuan, Tang, Sun, & Liu, 2020)、过滤意图(Arp et al. ., 2014;Cai, Li, & Xiong, 2021;Xu, Li, & Deng, 2016),以及硬件组件(Arp et al., 2014)可以从此文件中提取。
“classes.dex”文件是应用程序的执行文件,处理此类文件通常有三种方法:
(1)通过反汇编方法将其转换为Smali语言代码,并提取API调用等特征( Aafer 等人,2013 年;Seraj、Khodambashi、Pavlidis 和 Polatidis,2022 年;Shen、Del Vecchio、Mohaisen、Ko 和 Taheri 等人,2018 年; 2020;Yerima、Sezer 和 Muttik,2015;Zhu、Gu、Wang、Xu 和 Shen,2023),控制流图(Allix、Bissyandé、Jérome 等,2016;Xu 等,2018、2019),函数调用图(Xu 等人,2018、2019)和 Android 意图(Feizollah、Anuar、Salleh、Suarez-Tangil 和 Furnell,2017;Idrees、Rajarajan、Conti、Chen 和 Rahulamathavan,2017;Kouliaridis、Potha, & Kambourakis,2020;Taheri 等人,2020);
(2)通过反编译的方法获取Java源代码,然后利用文本分析或其他方法提取特征(Milosevic et al., 2017;Song et al., 2019);
(3)直接将“classes.dex”的二进制代码视为原始特征(Amin et al., 2020;Hsien-De Huang & Kao, 2018;Ren, Wu, Ning, Hussain, & Chen, 2020; Yadav、Menon、Ravi、Vishvanathan 和 Pham,2022;Yuan、Wang 等人,2020;Zhu、Wei、Wang、Xu 和 Shen,2023)。其中一些方法,例如控制流图和函数调用图,是基于图模型的,这些方法将在 2.2 节中讨论。
传统的静态方法通常从APK文件中提取全局特征向量,然后利用机器学习模型对特征向量进行分类。共同特征主要包括权限(Milosevic et al., 2017; Şahin et al., 2021; Seraj et al., 2022; Talha et al., 2015; Yuan, Tang et al., 2020; Zhu, Gu et al., 2023)、意图(Feizollah 等人,2017;Idrees 等人,2017;Kouliaridis 等人,2020;Taheri 等人,2020)、意图过滤器(Arp 等人,2014;Cai 等人,2021) ;Feizollah 等人,2017;Xu 等人,2016),API 调用(Aafer 等人,2013;Alazab 等人,2020;Shen 等人,2018;Taheri 等人,2020;Yerima 等人) ., 2015; Zhu, Gu et al., 2023) 和语义特征 (Milosevic et al., 2017; Song et al., 2019)。通过分析提取的权限集合来提取权限特征,选择重要的权限作为特征。意图和意图过滤器也是常用的检测功能。具体来说,意图信息是从“classes.dex”文件中获取的,该文件封装了应用程序的调用意图,例如启动活动或服务。意图过滤器在“AndroidManifest.xml”文件中定义,用于指定应用程序可以接收的意图类型(Feizollah 等人,2017)。 API 调用特征通常是从“classes.dex”文件中的 API 调用序列中提取的。塔赫里等人。 (2020)从APK文件中提取权限特征、API特征和意图特征,形成二进制特征向量。使用随机森林回归器进行特征选择后,通过相似性计算进行检测。
语义特征(Milosevic 等人,2017;Song 等人,2019)和字节流中的 n 元语法特征(Karbab、Debbabi、Derhab 和 Mouheb,2020)用于检测 Android 恶意软件。米洛舍维奇等人。 (2017)首先获得Java源代码,并使用词袋方法从源代码中提取特征。然后,使用支持向量机和其他模型来执行二元分类。宋等人。 (2019)从第三方库中删除类后对反编译的Java源代码进行分段,并构建主题模型以提取主题向量作为每个样本的特征。然后,使用SVM和XGBoost进行二元分类。卡巴布等人。 (2020)从“classes.dex”文件或APK文件中提取字节码的权限、API特征和n-gram特征,并在降维后使用聚类方法对其进行分类。
其他几个功能也用于 Android 恶意软件检测,即硬件组件(Arp 等人,2014 年;Zhu, Gu 等人,2023 年)、应用程序组件(Arp 等人,2014 年;Xu 等人,2016 年)、网络地址(Arp et al., 2014)和 Dalvik 指令(Chen, Mao, Yang, Lv, & Zhu, 2018)。 Arp 等人提出的 Drebin 方法。 (2014),基于包括硬件组件和权限在内的八种基本特征,使用特征嵌入形成特征向量;然后,基于SVM模型进行分类。陈等人。 (2018) 从 Smali 代码中提取 Dalvik 指令,并将 APK 文件表示为十种 Dalvik 指令类型的序列。提取n-gram序列作为特征后,使用随机森林等模型进行二元分类和恶意软件家族分类。 Wang、Zhao和Wang(2019)提取了七种静态特征,包括权限、意图过滤器和API调用,然后结合深度自动编码器和CNN(卷积神经网络)构建混合检测模型来对特征进行分类。 Kim、Kang、Rho、Sezer 和 Im(2018)提取了五种特征,包括 API 调用、权限和组件,并使用多模态特征融合网络进行二元分类。朱,顾等人。 (2023)提出了MSerNetDroid方法;他们提取了权限、硬件和 API 特征,将特征转换为图像,并使用他们提出的 MSerNet 进行分类。
APK 文件(或“classes.dex”文件)中的字节码是恶意软件基础数据,可以通过深度学习方法直接分类(Amin 等人,2020;Daoudi 等人,2021;Hsien-De Huang & Kao,2018;Yadav 等,2022;Yuan,Wang 等,2020;Zhu,Wei 等,2023)。达乌迪等人。 (2021)提出了DexRay方法;他们根据字节码的值将APK文件转换为二维图像,并使用CNN模型进行分类。袁,王等人。 (2020)首先从APK文件中读取字节序列,根据字节之间的相邻关系构建大小为256*256的马尔可夫传输概率矩阵;然后,使用 CNN 模型对恶意软件家族进行分类。朱伟等人。 (2023) 删除了标题和数据部分,将索引部分转换为图像,并使用他们提出的 MADRF-CNN 模型进行分类。
除了图像之外,序列(McLaughlin et al., 2017)或文本数据(Zhang, Tan, Yang, & Li, 2021)也可用于通过深度学习模型进行分类。麦克劳克林等人。 (2017) 从 APK 文件中提取操作码序列并使用 CNN 模型进行分类。张等人。 (2021)提出了TC-Droid方法。他们通过提取权限、服务、意图和接收者四类特征来构建文本信息,然后使用 TextCNN 模型进行分类。
这些方法通常只提取全局特征,缺乏局部细节特征。然而,恶意软件的恶意行为通常局限于特定区域,难以提取应用程序的显着区域特征。有些特征对于恶意软件检测很重要,例如权限特征和语义特征;因此,我们在检测方法中保留了这两种特征。
2.2.基于图模型的静态方法
与基于特征工程或语义特征的方法相比,图方法可以挖掘组件或不同应用程序之间的关系。可以使用两种图,其中同质信息网络(HIN)可以挖掘不同应用程序及其组件之间的关系,单个应用程序的图可以表示应用程序中组件之间的关系(Qiu等人) .,2020)。
对于基于 HIN 的方法(Gao 等人,2021;Hei 等人,2021),Gao 等人。 (2021) 使用所有可用数据构建了一张完整的图表。图中,应用程序及其API为节点,API之间的相邻关系以及应用程序与API之间的调用关系为边。 GCN 用于通过检测图中的异常节点来检测恶意软件。黑等人。 (2021)从应用程序中提取权限、API、类、接口等,并将组件和应用程序用作HIN中的节点。他们通过节点嵌入模型从 HIN 中提取应用程序的特征,然后进行分类。
介绍别人的方法
对于基于内部组件图的方法,控制流图 (Allix, Bissyandé, Jérome et al., 2016; Wu, Wang, Li, & Zhu, 2016; Xu et al., 2018, 2019),数据流图 (Xu等人,2018,2019)、API 调用图(Pektaş & Acarman,2020)和函数调用图(Vinayaka & Jaidhar,2021)被研究人员广泛使用。 CSBD方法由Allix、Bissyandé、Jérome等人提出。 (2016)提取了APK文件的控制流图,从图中提取了基本块,然后将每个APK文件表示为一组基本块。根据每个样本中是否存在某个基本块来构造二值特征向量。特征选择后,使用C4.5和随机森林等模型进行二分类。徐等人。 (2018)从APK文件中提取控制流图和数据流图,将它们与权重组合,并使用CNN模型对图的邻接矩阵进行分类。 Vinayaka 和 Jaidhar (2021) 使用 APK 文件中的方法作为节点构建函数调用图,并使用度特征、方法属性和方法摘要信息作为节点特征。然后,他们用图卷积网络(例如GCN和GAT)提取节点特征,使用每个节点特征的平均值作为图特征,并进行二元分类。除了上面的图之外,还有一些其他类型的图构造。裴等人。提出了 AMalNet 方法(Pei, Yu, & Tian, 2020),从 APK 文件中的结构、组件和 API 信息中提取单词、字符和词汇特征的 m 维特征。然后,基于m维特征构建图,每个维度特征作为一个节点。最后,他们使用 GCN 对恶意软件类型进行分类。
在许多基于调用图的检测方法中,图仅包含节点之间的关系,从而排除了节点特征(Pektaş&Acarman,2020;Xu等人,2018,2019)。然而,恶意软件的恶意行为通常仅限于特定区域,这些方法无法准确表示显着区域特征。 Vinayaka 和 Jaidhar (2021) 引入了三种类型的节点特征,但这些特征是基于语义信息有限的简单统计来获得的。在本文中,我们使用之前提出的主题模型方法(Song et al., 2019)来构建类集调用图,并使用主题向量作为节点特征。然后,通过 GAT 网络使用最大池化方法从图中获得显着区域特征。该方法有效地结合了语义特征和结构信息。
2.3.动态方法和混合方法
动态方法通过在实际或模拟环境中运行 APK 文件来提取特征,最常见的动态特征包括 API 调用 (Jerbi, Dagdia, Bechikh, & Said, 2020)、系统调用 (Burguera, Zurutuza, & Nadjm-Tehrani, 2011) ;John、Thomas 和 Emmanuel,2020;Xiao、Zhang、Mercaldo、Hu 和 Sangaiah,2019),内核调用(Wang 和 Li,2021),和网络行为(Wang,Chen et al.,2019;Wang et al.,2017)。混合方法(Alzaylaee, Yerima, & Sezer, 2020;Arshad et al., 2018;Han, Subrahmanian, & Xiong, 2020;Zhou, Wang, Zhou, & Jiang, 2012)集成静态和动态特征来描述对象的各个方面。应用。
大多数动态方法通过执行应用程序来提取API调用、系统调用、内核调用和网络行为等特征,并使用机器学习模型进行分类。动态方法可以分为基于传统机器学习的方法和基于深度学习的方法。
在传统的基于机器学习的动态方法中,特征主要包括系统调用特征(Burguera et al., 2011; Surendran et al., 2020)、内核调用特征(Wang & Li, 2021)和网络流量特征(Wang,陈等人,2019;王等人,2017)。对于系统调用和内核调用,通常使用以下方法提取特征:通过计算每种调用类型的出现次数(Burguera et al., 2011)、根据方法调用序列构建调用图进行检测(Surendran等人,2020),并在机器学习模型运行时提取内核参数(Wang & Li,2021)。对于网络流量,可以对数据流进行分段,并可以使用n-gram等方法进行特征提取(Wang et al., 2017)。
在基于深度学习的动态方法中,大多数方法从应用程序中提取特征向量并基于深度学习模型进行分类。一般的方法包括使用深度学习模型对系统调用特征进行分类(Zhou et al., 2019)、直接使用系统调用序列作为自然语言句子进行分类(Xiao et al., 2019)以及使用图卷积网络来获得相应的系统调用图(John et al., 2020)。
混合方法分别从应用程序中提取静态和动态特征,以获得不同角度的综合特征(Alzaylaee et al., 2020;Han et al., 2020;Zhou et al., 2012)。韩等人。 (2020)获得120维静态特征、171维API包调用特征、767维动态特征;然后,他们提出了三种不同的特征转换方法,并使用随机森林模型对特征进行分类。
3. 多模态特征融合的检测方法
在本节中,首先介绍我们方法的动机和模型的整体结构。然后详细描述了类集调用图(CSCG)的构造方法。最后,我们介绍了基于GAT的CSCG图特征提取,以及使用深度网络将CSCG特征与权限特征融合。
3.1.动机
在静态 Android 恶意软件检测中,常见特征包括“AndroidManifest.xml”文件中的权限特征以及“classes.dex”文件中的语义和结构特征。不同的特征类型可以支持不同的分析视角。多模态特征的融合可以有效地表征恶意软件的特征,并且可能比使用单一类型的特征产生更好的检测结果。因此,本文重点研究多模态特征的深度融合,如图1所示。
我们之前的工作(Song et al., 2019)验证了主题模型可以有效地提取代码语义特征。然而,该方法从应用程序中提取全局主题向量。由于恶意软件的恶意行为通常发生在特定的代码区域,全局主题特征无法准确表示显着区域特征。因此,我们构建一个调用图,其中的节点对应于应用程序代码的特定单元,并提取节点的主题向量作为节点特征。然后,我们使用带有最大池化的GAT模型来提取显着区域特征作为整个图的特征,从而有效地融合节点特征和结构信息。
传统调用图中的每个节点通常代表一个函数。然而,Java 函数可能包含的单词太少而无法提取有效的主题特征。因此,我们首先选择每个类作为一个节点,进一步将一些类节点合并为类集节点并构建类集调用图(CSCG)。因此,增强了每个节点的语义信息,并减少了调用图的规模。如图1所示,我们假设一个包含17个Java文件的APK文件,在节点合并后,我们可以归档一个包含8个节点的CSCG。该示例的详细信息如第 3.3.5 节所示。
此外,权限功能被广泛使用,对于 Android 恶意软件检测非常重要。 CSCG 的图特征和权限特征差异很大,并且单独的相关性可能较低。因此,我们通过深度特征融合网络融合这两种特征,然后使用深度神经网络直接对融合后的特征进行分类。对于特征融合网络,Kim 等人。 (2018) 应用单融合点网络(直接串联不同类型的特征)进行 Android 恶意软件检测。此外,Gu、Lang、Yue和Huang(2017)实验验证了多个融合点的使用,它采用不同类型特征的多级串联,并且在图像模式识别中比使用单个融合点产生更好的结果。因此,我们为我们的检测方法构建了一个多融合点网络。
3.2.模型结构
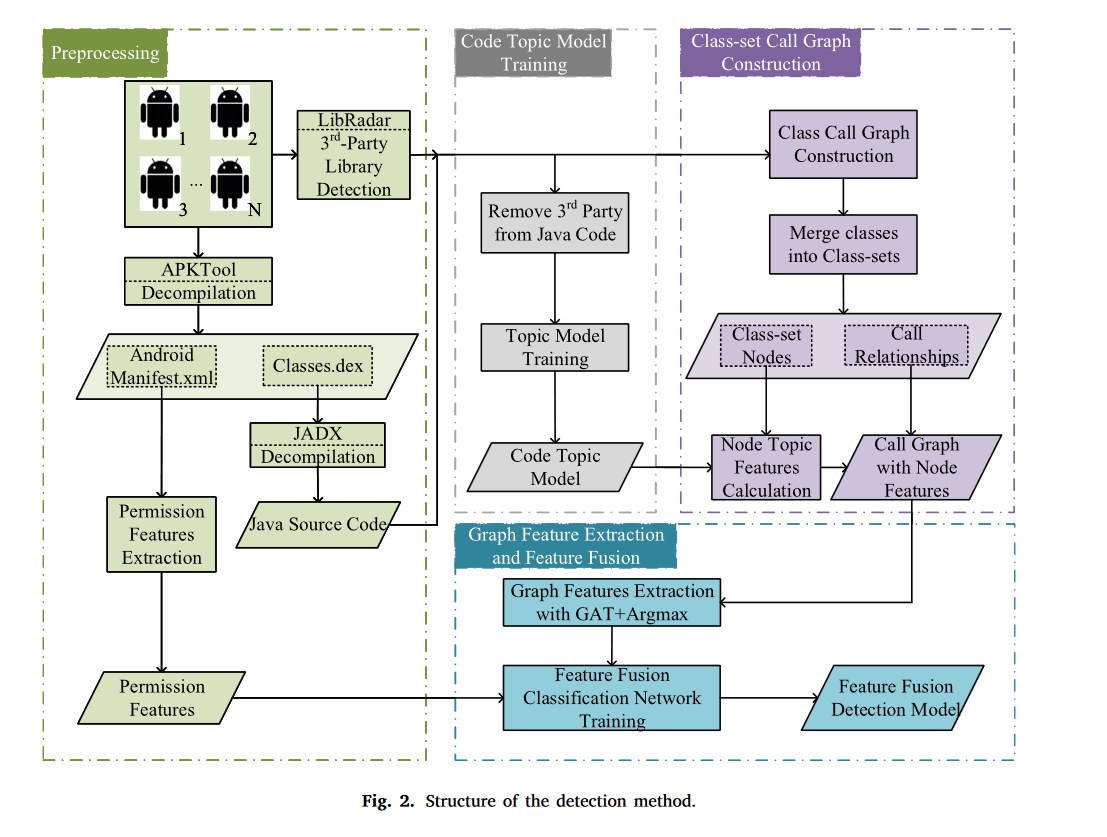
我们的检测方法的结构如图2所示。该模型分为四个部分:数据预处理、代码主题模型训练、CSCG构建、图特征提取和多特征融合。
数据预处理
我们首先使用 APKTool(Winsniewski,2012)对 APK 文件进行反编译,得到 “AndroidManifest. xml” 和 “classes.dex” 文件,使用 LibRadar(Ma,Wang,郭,&Chen,2016)检测 APK 文件中包含的第三方库,然后使用 JADX(Skylot,2014)对 “classes.dex” 文件进行反编译,得到 Java 的源代码。然后,根据 StursDroid(Chen,薛,唐,徐,& 朱,2016)给出的 59 个高危权限,从 “AndroidManifest.xml” 文件中提取出 59 维权限特征,包括位置权限 “ACCESS_FINE_LOCATION” 和网络权限 “ACCESS_WIFI_STATE”。可能存在多个同名权限,例如,“READ_SETTINGS” 权限,及其详细权限,包括 “android. 权限。READ_SETTINGS” 和 “com.android.Launcher. 权限。READ_SETTINGS”。这些同名权限可能出现在同一个 “AndroidManifest. xml” 中,所以我们使用每个权限的出现次数作为对应的权限特征。
代码主题模型训练
这部分过程与我们之前的工作中使用的一致(Song et al., 2019)。首先,我们从Java源代码中删除了第三方库中的代码,并使用Java词法分析器对剩余源代码进行了分段。分段结果中仅保留标识符、字符串和数字。每个样本最多保留 100,000 个单词。接下来,我们根据训练数据集训练TF-IDF模型,在TF-IDF模型的词典中保留10万个单词,得到TF-IDF特征向量。最后,我们训练了LSI(潜在语义索引)模型作为主题模型,保留了500个主题。然后,我们计算全局LSI特征向量。随后使用LSI模型和全局LSI向量构建CSCG。
CSCG构建
对于每个 APK 文件,我们构建了一个使用 Java 源代码的公共类构建的类调用图。然后根据Java包结构和第三方库检测结果,对节点即类进行合并;因此,每个新节点代表一个类集。合并后构建的CSCG在一定程度上减少了节点数量。最后,计算每个类集的LSI向量以建立节点特征。 CSCG 的构建将在第 3.3 节中详细讨论。
图特征提取和多特征融合
我们使用带有最大池化的GAT模型从CSCG中提取显着区域特征作为图模型的特征;这个过程涉及语义模态和结构模态特征的融合。然后,将权限特征作为权限模态特征,构建多融合点网络来融合特征并进行分类。一个融合点表示不同类型特征的串联,多个融合点表示多个级别不同类型特征的串联。总体而言,创建了一种端到端检测方法,包括使用 CSCG 进行特征提取、多模态特征融合和分类。检测模型在3.4节中详细介绍。
我们的源代码位于:GitHub - chenshaojie-happy/Android_Malware_Detection_Method_Based_on_Graph_Attention_Networks
3.3 CSCG构建
本节我们详细介绍CSCG的构建方法。我们首先介绍我们的构建方法的概述。然后,我们介绍了节点合并方法,并且我们单独介绍了节点合并方法中的自适应节点大小计算。之后,我们展示了节点特征提取和边缘构建方法。最后,我们给出了我们的CSCG构建方法的一个例子。
3.3.1.概述
我们首先根据类之间的调用关系构建类调用图。每个类相当于一个Java文件,被视为图中的一个节点。然后,我们将某些节点合并为一个节点并构建类集调用图(CSCG)。为了增强CSCG中每个节点的语义信息并控制图的规模,我们在构造CSCG时设置了节点数量的上限ts_max和下界ts_min。 ts_max和ts_min可以根据计算资源和数据集中的APK文件大小来设置。在 Java 语言中,包为相关接口和类创建分组(Arnold 等人,2005)。因此,在反编译后的Java源代码中,同一个包中的文件的语义会比不同包中的文件的语义更加相似。因此,基于Java包结构,我们将同一个包中的Java文件合并,以保证单个类集中语义的一致性。
第三方库可能会干扰主题向量的代表性;然而,第三方库中的代码也可能包含恶意行为,删除它们可能会导致调用关系不完整。因此,为了减少第三方库节点的比例,在合并节点时,我们尝试将每个第三方库合并为一个类集节点,并将非第三方库的文件分离为多个类集节点:尽可能多。即当非第三方文件数量达到ts_min时,将每个第三方库直接合并为一个class-set节点;当非第三方文件数量不足时,应适当分离第三方库,使class-set节点数量达到ts_min。这样,减少了第三方库对应的类集节点的比例,减少了第三方库的影响。
根据ts_max、ts_min和第三方库检测结果计算每个APK文件的节点尺寸k(单个类集节点包含的文件/类的数量),确保所有非第三方类集节点包含大致等量的信息。由于APK文件的规模差异较大,为了避免获得许多CSCG中带有ts_max节点的大APK文件,这可能导致规模和结构信息的丢失,我们设计了一种自适应算法来自动确定k的值特定的 APK 文件。该算法对APK文件的类调用图进行按比例缩减,从而有效地保留与每个图相关的结构和大小信息。
获得合并的类集节点后,我们计算节点特征的主题向量。然后,将基本类调用图之间的调用关系作为边映射到CSCG。
接下来介绍CSCG建设的关键步骤。
3.3.2.节点合并以构造类集节点
为了将代码调用图中的节点数量减少到可接受的范围,我们设计了一种类集构造方法,将同一包下的k个Java文件适当地合并为一个类集。这里,k表示类集节点的大小,并且是根据Java文件的数量和相应的阈值针对每个APK文件动态计算的。 k的计算过程将在3.3.3节中介绍。构建满足 ts_max 和 ts_min 约束的 CSCG 的另一个问题是控制不同大小的 APK 文件的第三方库节点的数量,以便 CSCG 能够表示尽可能多的来自非第三方文件的信息。
我们的策略是确保每个 APK 文件的类集节点数量在 [ts_min, ts_max] 区间内(Java 类少于 ts_min 的 APK 文件除外)。我们将一个APK文件的所有Java文件视为一个初始节点,并逐步分裂该节点,直到节点数量满足相关要求。根据Java文件的结构,我们优先拆分非第三方的包。对于每个非第三方包,包中每k个文件视为一个类集节点,每个第三方库包视为一个类集节点。然后,如果所有非第三方包都被拆分,但类集节点数小于 ts_min,则对第三方包进行适当拆分,直到类集节点数达到 ts_min 或者没有包可供拆分。分裂。
对于此拆分任务,一种简单的方法是对 Java 包结构执行深度优先遍历。然而,由于每个包中包含的文件数量一般不是k的整数倍,这会导致大量大小小于k的类集节点,因此分裂过程可能会因为ts_max的限制而过早停止。如果发生这种提前停止,一些大节点将保持未分裂状态,导致节点大小不均匀。为了避免这个问题,我们迭代地分割包含最多文件的最大节点,而不是递归分割。对于每次迭代,仅将选定的包拆分为下一级包,以确保每次迭代中拆分最大的节点。
拆分过程如图3所示。我们首先将一级包设置为初始类集节点,例如“com/”和“android/”,并将类集节点保存在命名节点的列表。在每次迭代中,非第三方节点先于第三方节点进行分裂;然后,将包含最多文件的节点进行分裂,并将分裂结果更新为节点。分裂时,如果一个节点不包含下一级包,则该节点中的每k个文件被划分为单独的节点;否则,每个包将形成一个节点。重复此迭代,直到满足以下条件之一:(1)没有要分裂的节点,(2)节点数大于ts_max,或(3)没有非第三方节点要分裂并且节点数达到ts_min。
我们构造的最优CSCG的节点数在区间[ts_min, ts_max]内;另外,所有节点中包含的信息量尽可能相等。在实践中,我们将ts_min设置为100,以确保有足够的节点来保留足够的结构信息。我们首先根据服务器的计算能力将 ts_max 设置为 1500,然后调整它以找到每个数据集的最佳值。
3.3.3.自适应类集节点大小
不同APK文件中包含的公共类数量差异很大,少则不到10个,多则数万个。因此,对所有 APK 文件使用固定的类集节点大小是不合理的。
节点大小k可以与类调用图和CSCG之间的缩减比率相关。在将Java文件划分为类集之前,我们首先计算非第三方Java文件的数量file_num_not_3rd和第三方包的数量pk_num_3rd,并将相应的总和命名为sum。仅当 k 取区间 [ ⌈sum/ts_max⌉, ⌊sum/ts_min⌋ ] 内的值时,节点数才能在区间 [ts_min, ts_max] 内(⌈ ⌉ 和 ⌊ ⌋ 分别表示向上取整和向下取整) )。许多 k 值都满足此条件,并且对于不同的 k 值,所得的 CSCG 可能会有很大差异。
许多 APK 文件包含大量 Java 文件。如果直接将节点大小计算为⌈sum/ts_max⌉,则会出现很多带有ts_max节点的CSCG,导致APK大小信息丢失。然而,通过对相关数据的统计分析,我们发现APK大小信息很重要。一般来说,恶意软件样本的平均大小小于良性样本的平均大小。例如,Apkpure(Apkpure Team,2020)的良性样本平均包含 6589 个 Java 文件,中位数为 5724 个文件,而同一时间来自 VirusShare(Virusshare,2020)的恶意软件样本平均包含 1644 个文件,平均包含 1644 个文件。文件的中位数为 388 个。因此,我们提出了一种方法来实现不同尺度下调用图的按比例缩减。
在计算节点大小k时,首先根据整个数据集单个APK文件中Java文件数量的分布来设置min_k。 min_k是数据集中k的最小值,即调用图的最小缩减比例。因此,每个调用图的缩减比例相对相似,以尽可能保留尺度差异信息。然后,对于每个APK文件,我们根据Java文件的数量动态自适应地计算k,min_k,ts_min和ts_max。
min_k的计算如式(1)所示。我们将整个数据集中的节点数映射到区间 [0, ts_max]。为了保留尺度差异,我们首先计算所有APK文件中Java文件数量的中位数,将中位数映射到ts_max/2,将整个数据集的中位数除以ts_max/2,并使用近似整数作为min_k。如果min_k计算为0,则将min_k设置为1。中位数是指一个APK文件中Java文件的中位数。
例如,对于 VirusShare_Apkpure 数据集,类的中位数约为 2812,ts_max 为 1500,因此我们为数据集设置 min_k = 2, 812∕(1, 500∕2)≈4。k的计算如式(2)所示。我们应该尝试将不同的和映射到[ts_min,ts_max]中,并实现按比例减少。对于不同区间的求和,需要以不同的方式计算k。比例缩减主要在sum ∈ [ts_min × min_k, ts_max × min_k) 时进行。 当sum在其他区间时,k受ts_min和ts_max限制。

3.3.4.节点特征提取和边缘构建
在类集节点构建之后,对于每个类集节点,利用主题模型计算500维特征向量。
然后,我们将类调用图中的边转换为相应类集节点的边。同一类集中的节点之间的调用关系将被忽略,仅保留其中一个重复关系。
CSCG可能包含许多独立的分支或孤立的节点,并且不同分支中的特征无法通过图卷积网络组合,这可能导致特征不完整。因此,我们通过添加虚拟根节点使该图成为全连接图。我们使用全局LSI特征作为根节点特征,然后添加从根节点到每个分支的最顶层节点的边。
此外,我们使用图卷积网络将CSCG转换为无向图以获得更好的图特征。在图卷积网络中,每个节点特征根据其相邻节点进行更新。如果使用有向图作为网络的输入,则每个节点特征仅根据其调用的节点进行更新,而与调用它的节点无关。然而,我们认为这两种类型的调用关系都会影响节点特征的更新;因此,我们将CSCG转换为无向图,并且我们的实验结果验证了这种方法。
3.3.5. CSCG构建实例
在这里,我们展示了 CSCG 构造的示例,如图 4 所示,其中不同步骤中的每个类集节点都使用相同的特定颜色进行标记。本例中,APK文件包含17个Java文件,如图4所示。第三方库集合为[''com/_3rd/''],ts_min为5,ts_max为20,min_k为整个数据集为2。构建过程分为以下步骤:
步骤1:计算Java文件之间的调用关系,得到基本类调用图。
步骤2:计算Java文件之间的合并关系。首先根据算法1确定APK文件的k值,非第三方文件与第三方包之和为12,计算出k值为2。然后进行类集构建采用方法对节点进行合并,得到7个类集节点(B-H)。类集节点中,H包含第三方库中的全部6个文件,其他节点最多包含k个文件。
步骤3:根据合并后的类集节点,计算类集节点之间的调用关系。
步骤4:利用Java词法分析器对17个类进行分词,得到每个类集节点对应的单词。然后,计算 7 个类集节点的 LSI 向量。
步骤 5:添加全局 LSI 特征作为根节点 A。由于 3 个类集节点 B、C 和 D 没有被任何其他类集节点调用,因此我们添加从 A 到 B、C 的边,并且D.然后,将调用图转换为无向图作为最终的CSCG。
3.4.图特征提取与多模态特征融合
GCN(Kipf & Welling,2016)和 GAT(Veličković et al.,2017)通常用于图分类。主要目标是聚合相邻节点的特征并更新当前节点的特征。 GCNs的核心思想是基于拉普拉斯矩阵的特征分解。 GAT 使用注意力方法来计算每个邻居节点的权重。由于拉普拉斯矩阵的限制,GCN 只能用于无向图的卷积,而 GAT 可以用于有向图的卷积。与GCN相比,GAT模型通过引入注意力机制,可以更好地整合节点之间的相关性,从而提高建模性能。
因此,我们使用GAT模型提取CSCG的特征。 GAT 模型由 Veličković 等人提出。 (2017) 并已用于节点特征计算和节点分类应用。要应用GAT进行图分类,需要根据节点特征获得整个图的特征。 Knyazev、Lin、Amer 和 Taylor (2018) 使用最大池化来提取整个图特征。由于恶意软件的恶意行为通常发生在特定的代码区域,因此使用所有节点特征的平均值可能会掩盖显着区域的特征。因此,使用最大池化从整个图中的每个维度提取特征。我们结合 GAT 模型和最大池化提出了一个名为 Max-GAT 的调整网络。如图5所示,Max-GAT基于GAT获得的所有节点特征,通过最大池化从每个维度提取最大数量的特征,并将结果作为CSCG特征。
在Max-GAT的设计中,我们通过实验验证了单层GAT比多层GAT表现更好。因此,对于类集节点,一阶邻居比二阶邻居对结果的影响更大,并且二阶邻居可能会引入额外的噪声;因此,我们选择单层GAT模型进行特征提取。
在图5中,每个CSCG表示为 n*n 邻接矩阵和 n*500 节点特征矩阵,其中500是特征维度,n是节点数量。首先,根据调用关系,识别每个节点的一阶邻居,并使用GAT构建多头注意力机制,通过应用多个独立的注意力机制来增加模型的容量。在图5中,注意力头的数量用从一个相邻节点到每个中心节点的箭头数量表示,并作为一个重要参数进行调整。对于每个注意力头,首先对所有节点特征进行变换,然后对于每个节点,使用相邻节点特征的加权平均来获得更新的特征。将多头图卷积得到的特征的平均值作为最终特征。然后得到n*128的特征矩阵,通过最大池化,选择最大特征向量(128维)作为全图的特征向量。
为了融合图模态和权限模态特征,我们设计了一个多层深度网络,如图6所示。每层的大小(输出特征维度)在括号中表示。对于APK文件,首先获取CSCG,然后计算初始128维图模态特征向量。选择59维权限特征向量作为初始权限模态特征向量。两个模态特征之间的显着尺寸差异不利于特征融合。因此,为每个模态特征引入全连接层以减少这些差异。然后,我们构建一个三层神经网络,每层作为融合点,并从 F C3_F us 获得 64 维融合特征。通过最终的全连接层F C_out 得到最终的二分类结果。
3.5.时间复杂度分析
我们的方法主要包括三个部分:
(1)CSCG的节点合并;
(2)CSCG的节点特征提取和边构建;
(3)图特征提取、权限特征融合与分类。下面将分别计算这三部分的时间复杂度。假设一个APK文件包含m个Java文件,CSCG中的节点总数为n(n≤ts_max),一个Java文件的平均大小为s。
第一部分是CSCG的节点合并。在实现节点合并方法时,将APK文件中的所有Java文件按字母顺序排序,以保证每个节点内部Java文件的顺序,从而更容易进行节点拆分。之后,在每次迭代中,我们从现有节点中选择一个节点并将其拆分,直到达到结束条件。因此,其时间复杂度可以分为四个步骤:(1)Java文件排序,(2)分裂总次数,(3)选择分裂节点,(4)分裂节点。
这四个步骤的时间复杂度如下: (1) 文件排序的时间复杂度接近O(m × log(m))。 (2)根据我们的构造方法,节点分裂的数量最多为n,对应的时间复杂度为O(n)。 (3)对于每一次节点分裂的过程,我们都需要遍历已有的节点来寻找进行分裂的节点。节点数随着迭代而增加,且小于n,因此时间复杂度不超过O(n)。 (4)分裂节点时,需要将该节点内的所有文件一一划分为子组,一个节点内的文件数量小于m,时间复杂度不超过O(m)。因此,节点合并的总体时间复杂度小于 O(m × log(m)) + O(n) × (O(n) + O(m));由于 n ≤ m,类集构造的总体时间复杂度小于 O(m × log(m)) + O(m × n)。
下一部分是CSCG的节点特征计算和边构建。这部分的时间复杂度可以分为四个步骤:(1)进行词法分析,计算调用关系; (2)合并调用关系; (3)总结每个节点的单词; (4)计算LSI向量。
这四个步骤的时间复杂度如下: (1)在进行词法分析、计算类之间的调用关系时,需要遍历读取每个Java文件。时间复杂度为O(m×s)。 (2)合并类的调用关系时,关系数量小于
最后一部分是图特征提取、权限特征融合和分类。在模型的测试阶段,我们需要输入CSCG和权限特征来获得分类结果。除了Max-GAT之外,其余部分的时间消耗可以认为是一个常数,其时间复杂度大致为O(1)。由于Max-GAT的计算复杂度仅与CSCG中的节点数有关,用n表示。这些关系表示为 n * n 邻接矩阵,图特征提取的时间复杂度为 O(n2)。
总结以上三部分的时间复杂度,我们的方法的整体复杂度小于
4. 实验
我们进行了大量的实验来证明我们提出的检测方法的有效性。我们构建了三个数据集并进行了九组实验,包括对比实验和消融研究等,并对结果进行了分析。
4.1.数据集和指标
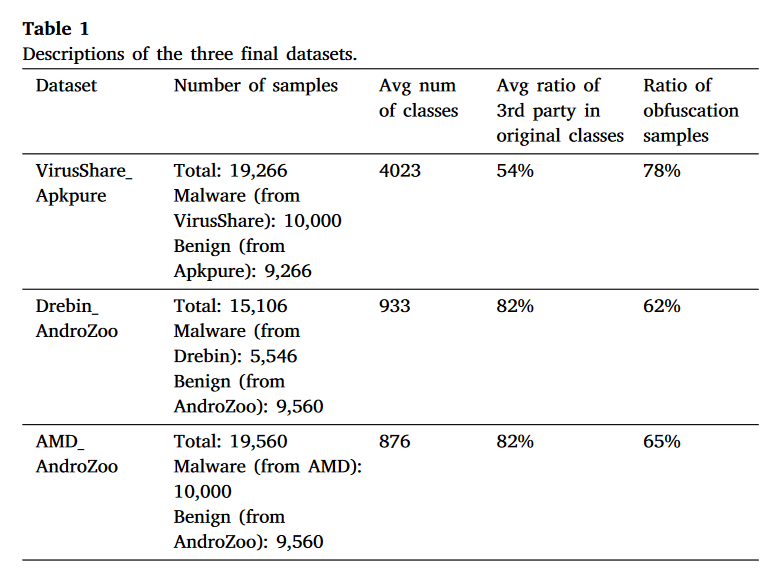
目前,Android 恶意软件数据集没有公开的完整数据集;因此,我们根据现有的良性和恶意软件数据集构建数据集。我们使用三个恶意软件数据集和两个良性数据集来构建三个最终数据集。三个恶意软件数据集如下:
(1) VirusShare(Virusshare,2020)。该数据集包含主要系统平台的恶意软件信息,自2012年开始生成。我们于2021年1月下载了两个最新的压缩包。
(2) Drebin (Arp et al., 2014)。该数据集基于涉及 179 个不同恶意软件系列的 Android 应用程序,收集时间为 2010 年 8 月至 2012 年 10 月。
(3) AMD(Wei、Li、Roy、Ou 和 Zhou,2017)。 AMD(Android 恶意软件数据集)数据集包含 24,553 个恶意软件样本,属于 71 个不同恶意软件家族的 135 个变体。数据收集于2010年至2016年。
两个良性数据集如下:
(1)Apkpure(Apkpure Team,2020)。我们于 2021 年 1 月从“apkpure.com”下载了 49 个主要类别中每个类别的前 25 个页面的“.apk”格式(不包括“.xapk”格式)样本,删除了大于 100 MB 并经过 VirusTotal 验证的样本(Virus Total,2012)。
(2) AndroZoo(Allix、Bissyandé、Klein 和 Le Traon,2016)。我们于 2018 年从 AndroZoo 平台下载了第一批 SHA256 排序的 10,000 个样本,并通过 VirusTotal 进行了验证(Virus Total,2012)。
我们计算了所有样本的 SHA256 值,并确认两个良性数据集中的每个样本均未在三个恶意软件数据集中找到。
根据采集时间将上述5个数据集进行组合,构建最终的3个数据集,如表1所示。由于Drebin和AMD采集时间较早,因此选择时间上更接近的AndroZoo与其进行组合。后来收集了VirusShare,所以选择了Apkpure与之结合。混淆技术在构建 APK 文件时被广泛使用。为了粗略评估我们的方法对混淆的 APK 文件的效果,我们计算了三个数据集中混淆的 APK 文件的比例。根据 He、Yang、Hu 和 Wang(2019)以及 Derr、Bugiel、Fahl、Acar 和 Backes(2017)的观点,我们认为以一两个字符或多个相同字符命名的类是混淆的。然后,我们设置一个阈值;当一个APK文件包含十个以上混淆类时,我们将其标记为混淆。
我们将数据集分为两个子数据集,其中 80% 的数据用于训练,20% 用于测试。我们使用准确度(A)和F-Measure(F1)作为模型评估的指标。
4.2.实验设置
我们的实验环境如下:
(1)CPU:AMD Ryzen ThreadRipper 3990X,
(2)内存:128 GB DDR4,频率为2400 MHz,
(3)存储:INTEL 665P NVME 1 TB,
(4)GPU:NVIDIA RTX 2080Ti
(5)操作系统:Ubuntu 18.04。
在实验中,选择了八种方法进行比较,包括三种基于传统机器学习模型的方法和五种基于深度学习的方法。由于本文开发的方法是一种静态方法,因此仅考虑静态方法进行比较。我们选择了三种传统机器学习方法:
- Drebin (Arp et al., 2014) 方法基于传统特征工程
- CSDB (Allix, Bissyandé, Jérome et al., 2016) 方法基于调用图
- LSI+Permission 方法是我们在之前的工作 (Song et al., 2019) 中提出的,基于语义特征
对于基于深度学习的静态方法,选择了以下五种使用不同模态输入的方法进行比较:
- DexRay (Daoudi et al., 2021) 将 APK 文件转换为图像并使用这些图像作为输入
- Deep Android Malware Detection (McLaughlin et al., 2017)(标记为 DAMD)使用操作码序列作为输入
- MSerNetDroid (Zhu, Gu et al., 2023) 提取了三种类型的特征来构建图像作为输入
- TC-Droid (Zhang et al., 2021) 将特征视为文本并作为文本分类模型
- SAGEConv (Vinayaka & Jaidhar, 2021) 使用调用图作为输入
其中,我们认为 MSerNetDroid、TC-Droid 和 SAGEConv 是最先进的方法。在这些方法中,Drebin、CSBD、DexRay、DAMD 和 SAGEConv 使用开源代码进行测试。对于 DexRay、DAMD 和 SAGEConv,我们使用作者发布的原始实现进行实验;对于 Drebin 和 CSBD,我们使用了其他研究人员的重新实现(https://github.com/MLDroid/)。对于 TC-Droid,我们根据论文中的描述提取了四种类型的特征来生成文本数据,并使用 TextCNN 模型进行分类;对于 MSerNetDroid,我们使用了作者提供的源代码。
我们的实验可以分为五类:与现有方法的比较实验、消融实验、泛化测试实验、与防病毒扫描仪的比较实验以及效率比较实验。
(1)与现有方法的比较实验
我们将我们的方法与Drebin、CSBD、LSI+Permission、DexRay、DAMD、SAGEConv、TC-Droid和MSerNetDroid方法进行了比较。
(2) 消融实验
• 图构建的有效性实验。我们比较了基于不同 CSCG 构建方法的模型的性能,以验证所提出方法的有效性。
• 图特征提取的有效性实验。我们比较了使用不同图特征提取方法的模型的性能,以验证所提出的单层 GAT 的有效性。
• 图表尺度的有效性实验。我们比较了具有不同 ts_max 值的模型的性能。
• 特征融合的有效性实验。为了评估多模态特征融合网络的构建,我们比较了引入和未引入许可特征时的结果,并比较了不同融合模型的性能。结果用于验证所提出的多点融合网络的有效性。
• 每个功能的有效性实验。我们测试了每个单独功能(LSI 功能、GAT 网络和权限)的性能,以显示不同部分如何影响整体性能。
(3)泛化测试实验
我们另外于2022年6月1日从VirusShare下载了240个恶意软件样本和240个良性样本Apkpure,它们与我们训练集中的样本的时间跨度为17个月。我们直接在新的小数据集上测试 VirusShare_Apkpure 数据集的最终模型,以评估泛化能力。
(4) 与防病毒扫描仪的比较实验
我们另外从 CICMalDroid (Mahdavifar, Kadir, Fatemi, Alhadidi, & Ghorbani, 2020) 获取了 600 个恶意软件和 600 个良性样本,并将我们的模型与四个防病毒扫描仪在新数据集上的检测性能进行了比较。
(5)效率对比实验
我们基于AMD_AndroZoo测试集将我们的方法与八种对比方法的时间成本进行了比较,以展示不同方法的检测效率。
4.3.结果
4.3.1.与现有方法的对比实验
本实验基于三个数据集进行。我们模型的最终参数如表2所示。基于经验,将 𝑡𝑠_𝑚𝑖𝑛 和 dropout 率设置为默认值且不进行调整。根据4.3.2节中实验(3)的结果,为每个数据集选择最优的 𝑡𝑠_𝑚𝑎𝑥,而 𝑚𝑖𝑛_𝑘 则直接基于 𝑡𝑠_𝑚𝑎𝑥 和公式(1)计算得出。
需要调整的参数包括学习率和 GAT 注意力头的数量。在实验中,我们考虑了两个常用的学习率值 0.001 和 0.002,并尝试了 2-8 个注意力头的数量,以选择最优参数。在训练模型时,我们选择使用 Adam 作为优化器,将批次大小设置为 10;我们选择经过 50 轮迭代后的模型作为最终模型。
为了防止我们的模型过拟合,我们进一步将训练集分成两部分,其中 90% 的样本继续用作训练集,另外 10% 用作验证集以观察模型的拟合状态。我们确保在 50 轮迭代后,验证集上的准确率没有显著下降,并使用测试集上的结果作为最终结果。然而,根据我们的实验结果,在使用不同参数时,每个数据集的准确率差异基本都在 0.5% 以内。
对于每种比较方法,我们也测试了多组参数,并选择最佳结果作为最终结果。所有方法在三个测试集上的指标如表3所示。
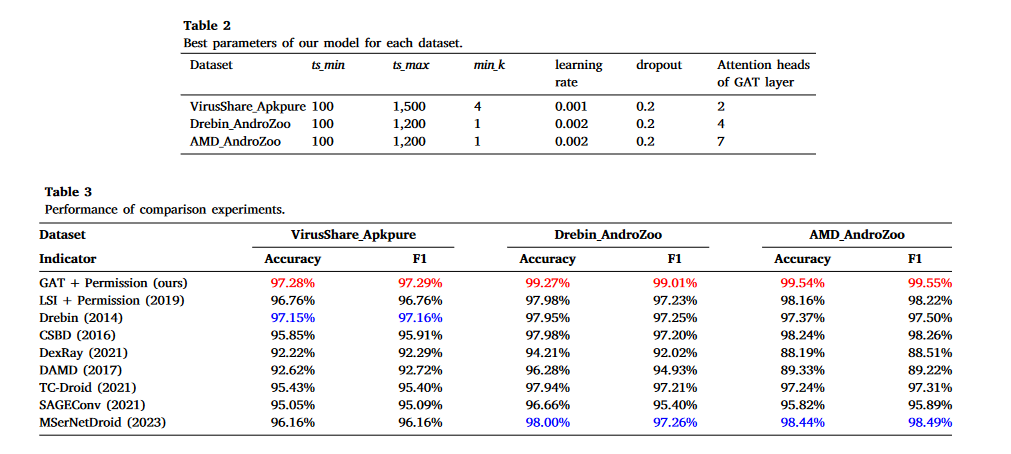
在所有实验结果表格中,最佳结果用红色显示,第二佳结果用蓝色显示。表3显示,我们的方法在三个数据集上都获得了最佳的准确率和F1值。
Drebin方法在 VirusShare_Apkpure 数据集上的准确率仅略低于我们的方法,但在其他两个数据集上,Drebin方法的准确率明显低于我们的方法。与四种深度学习方法相比,我们的方法达到了最佳的检测效果;与在这五种方法中表现最好的 MSerNetDroid 相比,我们的方法在准确率上提高了1.1-1.3%,在F1值上提高了1.0-1.8%。
此外,结果表明混淆技术对我们的检测效果没有显著影响。
在分析了各种方法之间的差异后,我们认为:
-
DexRay 方法直接将 APK 文件转换为图像并进行分类;它只需要简单的预处理,但无法达到良好的检测效果。
-
DAMD、TC-Droid 和 MSerNetDroid 方法提取序列、文本或二进制特征,然后使用深度学习模型进行分类;因此,检测效果在很大程度上受限于它们提取的原始特征。
-
Drebin 方法使用了八种类型的特征,所选特征全面,在三个数据集上都取得了良好的检测结果。
-
我们之前提出的 LSI + permission 方法使用主题向量来表示 Android 恶意软件的语义特征,这显示了主题模型的有效性。然而,这两种方法都提取了 Android 应用程序的全局特征,缺乏对局部特征的描述,也没有考虑结构特征。我们的方法通过引入类集调用图弥补了这一不足。
-
CSBD 和 SAGEConv 方法都基于图分类。CSBD 方法仅使用恶意软件的结构特征;虽然 SAGEConv 方法引入了图的节点特征,但其特征是基本的统计特征。与这两种方法相比,我们通过在结构信息之外引入 LSI 向量作为节点语义特征,提取了更有效的恶意软件特征。
4.3.2.消融实验
(1)图构建实验
本实验基于三个数据集比较了四种图构建方法的性能。这里,基于计算能力将 𝑡𝑠_𝑚𝑎𝑥 设置为 1500。这四种方法都使用单层 GAT 网络进行特征提取,并直接进行分类而不融合权限特征。此外,前三个模型都是无向图。这四种方法如下:
-
对所有数据集都不设置 𝑚𝑖𝑛_𝑘;即将 𝑚𝑖𝑛_𝑘 设置为默认值 1;
-
根据每个数据集中 APK 文件的规模设置 𝑚𝑖𝑛_𝑘。由于这些数据集中 Java 文件数量的差异,每个数据集的 𝑚𝑖𝑛_𝑘 不能设置为相同的值。三个数据集中 Java 文件的中位数如下:
- AMD_AndroZoo 约为 383
- Drebin_AndroZoo 约为 371
- VirusShare_Apkpure 约为 2812
AMD_AndroZoo 和 Drebin_AndroZoo 的中位数远低于 𝑡𝑠_𝑚𝑎𝑥 / 2,所以 𝑚𝑖𝑛_𝑘 设置为 1,与默认值相同。根据公式(1),VirusShare_Apkpure 的 𝑚𝑖𝑛_𝑘 值设置为 4。
-
在设置 𝑚𝑖𝑛_𝑘 后将根节点添加到 CSCG 中。
-
设置 𝑚𝑖𝑛_𝑘 并添加根节点,但使用有向图。
实验结果如表4所示。表4显示,使用设置了 𝑚𝑖𝑛_𝑘 并添加根节点的无向图模型取得了最佳结果。在为 VirusShare_Apkpure 设置 𝑚𝑖𝑛_𝑘 后,指标略有改善。此外,类集节点的平均数量从 500 减少到 470,减少了资源消耗。
我们比较了添加和不添加根节点的结果。添加根节点后,模型在所有三个数据集上表现更好。这一发现表明引入根节点提高了模型性能;特别是,根节点与最顶层节点之间形成了关系,并生成了一个完全连通的图。
无向图和有向图方法的结果显示,无向图比有向图表现更好。因此,对于一个节点,在特征更新时应同时考虑它调用的节点和调用它的节点。因此,在后续实验中,我们使用无向图作为 GAT 的输入。
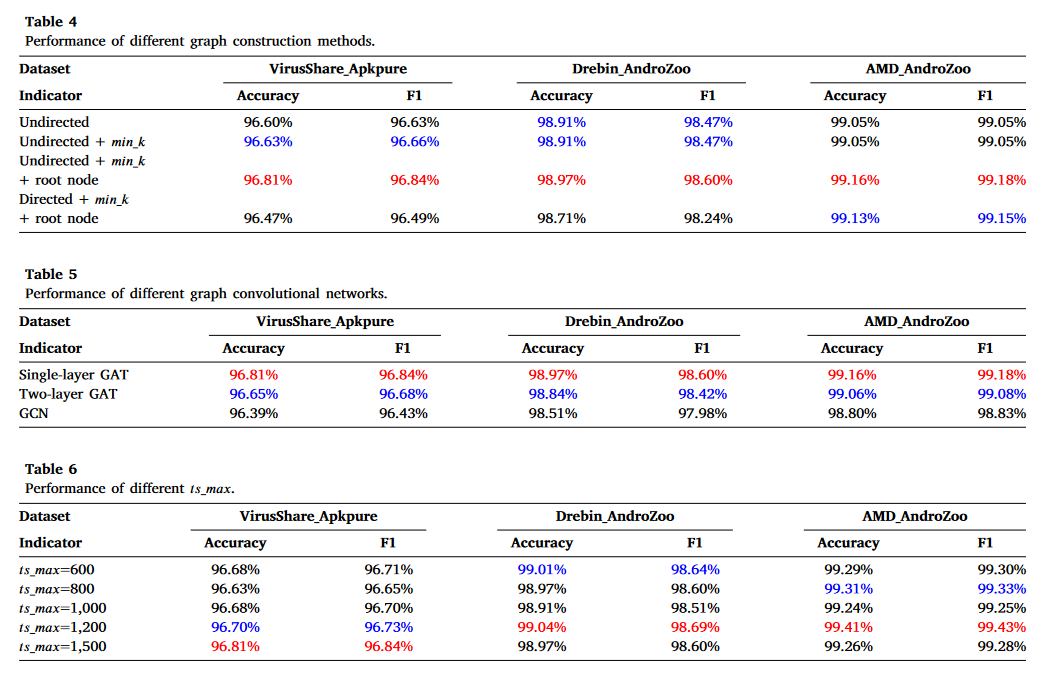
(2)图特征提取实验
本实验比较了使用三种图卷积网络的模型性能,这些模型都基于4.3.2节实验(1)中确定的最佳预处理方法,包括无向图、动态设置的 𝑚𝑖𝑛_𝑘 值和根节点的添加,且 𝑡𝑠_𝑚𝑎𝑥 设置为 1500。
这三个模型使用不同的图卷积网络来提取图特征,并直接进行分类而不融合权限特征:
- 单层 GAT 模型
- 双层 GAT 模型
- GCN 模型
实验结果如表5所示。表5显示单层 GAT 表现最佳。
我们比较了单层 GAT 和多层 GAT 的结果。值得注意的是,单层获得的结果优于多层图卷积操作后获得的结果,这表明一阶邻居比二阶邻居对结果有更大的影响。
对于单层 GAT 和 GCN 的结果,GAT 模型表现优于 GCN,主要是由于引入了注意力机制和邻居节点的权重。
(3)图尺度实验
本实验比较了五个不同 𝑡𝑠_𝑚𝑎𝑥 值的性能,以探究不同图尺度的影响。我们使用单层 GAT 模型获取不同尺度 CSCG 的特征,并在三个数据集上测试性能。实验结果如表6所示。
实验结果表明,最佳的 𝑡𝑠_𝑚𝑎𝑥 因数据集而异。三个数据集中 Java 文件的中位数差异很大:
- AMD_AndroZoo 约为 383
- Drebin_AndroZoo 约为 371
- VirusShare_Apkpure 约为 2812
因此,AMD_AndroZoo 和 Drebin_AndroZoo 的最佳 𝑡𝑠_𝑚𝑎𝑥 较小,而 VirusShare_Apkpure 的最佳 𝑡𝑠_𝑚𝑎𝑥 较大。由于服务器的限制,最大 𝑡𝑠_𝑚𝑎𝑥 只能设置为 1500。如果有更多的计算资源,我们可以为 VirusShare_Apkpure 尝试更大的 𝑡𝑠_𝑚𝑎𝑥。实验结果还表明 𝑡𝑠_𝑚𝑎𝑥 对检测性能的影响不大。
(4)特征融合效果实验
本实验比较了三种特征融合网络的性能。VirusShare_Apkpure 的 𝑡𝑠_𝑚𝑎𝑥 设置为 1500,而 Drebin_AndroZoo 和 AMD_AndroZoo 的 𝑡𝑠_𝑚𝑎𝑥 设置为 1200。我们使用单层 GAT 提取特征。这三种方法如下:
- 仅使用图特征进行分类;
- 使用单融合点网络融合图和权限特征,这相当于图特征和权限特征的串联。在图6中,这意味着直接使用 𝐹𝐶1_𝐹𝑢𝑠 的输出作为 𝐹𝐶_𝑜𝑢𝑡 的输入;
- 使用多融合点网络融合图和权限特征进行分类。
实验结果如表7所示。表7显示多融合点网络取得了最佳性能。特征融合方法通过引入权限特征可以有效提升模型性能。此外,多融合点网络在所有三个数据集上的表现都优于单融合点网络,这可能意味着使用多个融合点比使用单个融合点能够达到更好的融合效果。
(5) 单一特征的有效性实验
我们测试了模型中每个单独特征的性能,包括 LSI 特征、GAT 网络和权限特征,以展示不同部分如何影响整体性能。由于 GAT 网络需要节点特征,我们测试了 LSI+GAT。因此,我们比较了四种类型特征的性能:
- 仅 LSI 特征
- 仅权限特征
- LSI + GAT 特征
- LSI + GAT + 权限特征
LSI 特征和权限特征直接通过全连接层进行分类。这里,LSI + GAT 特征和 LSI + GAT + 权限特征等同于4.3.2节实验(4)中的设置,即仅使用图特征和多融合点。
实验结果如表8所示。从实验结果来看,我们方法的所有三个部分都对模型性能有影响。比较仅使用 LSI 和 LSI+GAT 的方法,在引入 GAT 模型后,模型的整体准确率提高了2.3%-3.8%,这证明了我们的 GAT 方法对模型效果有显著影响。
此外,仅使用权限特征的方法检测效果较低,但引入权限特征可以进一步提升模型效果。
4.3.3. 泛化测试实验
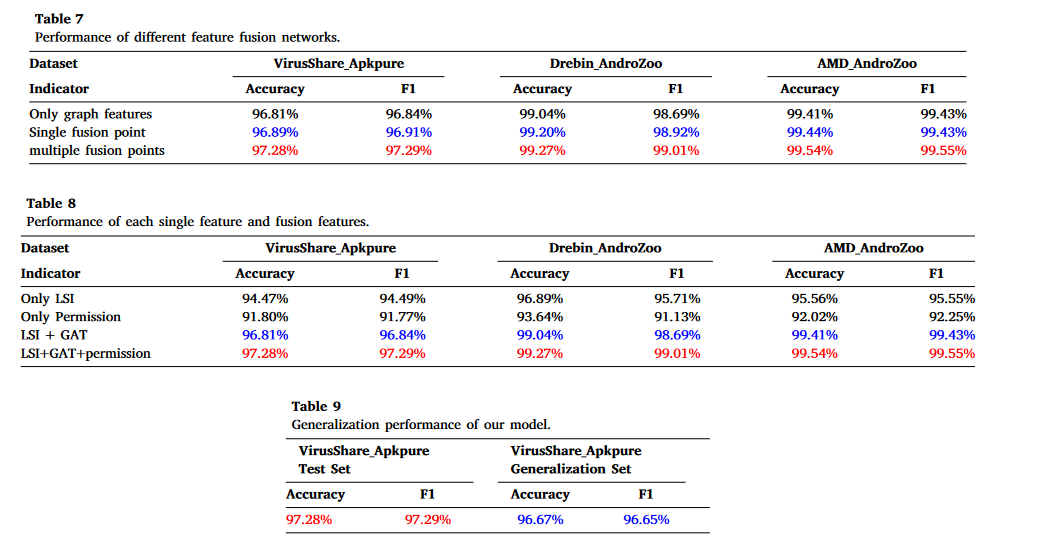
由于不同恶意软件家族差异很大,很难对所有恶意软件家族都达到良好的性能。恶意软件家族不断演变,各种变种快速更新。因此,类似于 Pei et al. (2020)、Yerima and Khan (2019) 的研究,我们在一段时间后使用测试数据集中恶意软件家族的新变种进行实验。
在我们使用的三个恶意软件数据集中,只有 VirusShare 仍在更新;我们选择 VirusShare_Apkpure 进行测试。我们在2022年6月1日额外下载了来自 VirusShare 的240个最新恶意软件样本和来自 Apkpure 的240个良性样本,这些样本与训练集样本有17个月的时间跨度。我们模型的实验结果如表9所示。尽管在有17个月时间跨度的相同来源数据集上结果略有下降,但我们的模型仍然保持了较高的准确率和F1分数。这表明我们的模型具有一定的泛化能力。
4.3.4. 与防病毒扫描器的比较实验
我们从 CICMalDroid (Mahdavifar et al., 2020) 获取了安卓应用样本,并将我们的方法与四个防病毒扫描器进行比较。CICMalDroid 的样本收集于2017年12月至2018年12月,包含良性样本和四类恶意软件:广告软件、银行木马、短信木马和风险软件。我们随机选择了600个良性样本,以及每类150个恶意软件样本来构建测试数据集。
我们选择使用在 AMD_AndroZoo 数据集上训练的最终模型进行检测,并确保我们选择的样本不包含用于模型训练的 AMD 数据集中的恶意软件。我们选择了四个防病毒扫描器进行比较:
- Kaspersky (AO Kaspersky Lab, 2023)
- Avast (Avast Software, 2023)
- 360杀毒 (360 CN, 2023)
- 火绒安全 (Beijing Huorong Network Technology, 2023)
比较的最终结果如表10所示。从结果来看,我们的方法在数据集上对四类安卓恶意软件的召回率都超过83%,且没有误报。就防病毒扫描器而言,Kaspersky 的性能最接近我们的方法。结果证明,我们用约15,000个样本训练的模型对这四类安卓恶意软件的检测效果优于防病毒扫描器。
由于样本是大约五年前获取的,防病毒扫描器可能已经为这些样本生成了适当的特征签名,它们的检测效果可能会随时间逐渐提高。
4.3.5. 效率对比实验 Efficiency comparison experiment
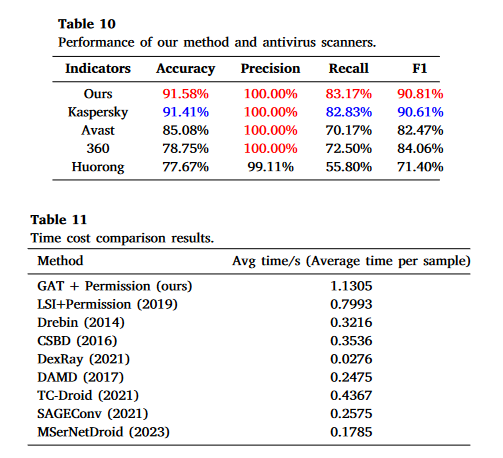
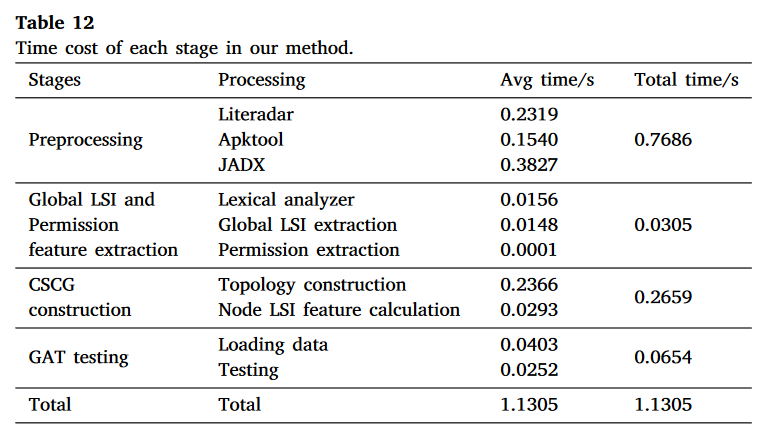
我们基于 AMD_AndroZoo 的测试集,将我们方法的时间开销与八种比较方法进行了对比。每种方法都在4.2节描述的服务器上运行,并尽可能地并行运行以提高检测效率。表11显示了每种方法的时间开销,表12显示了我们方法各阶段的时间开销。
在表11中,显示我们的方法在某种程度上需要更长的时间,这是因为我们为了达到更好的检测效果而进行了更多的操作。在比较方法中:
- DexRay 方法只需要读取字节流并将其转换为图像进行检测;它实现了最佳的检测效率,但无法达到良好的检测效果
- 其他七种方法需要进行预处理,这导致了更多的时间开销
表12显示,在我们的方法中:
- 预处理阶段消耗了大部分检测时间
- JADX 消耗最多时间
- 由于我们的方法包含三个预处理步骤,而比较方法通常只使用一个工具进行预处理,所以它们的时间开销相对较短
我们认为我们的方法仍然可以满足实际的实时性能需求,并且在运行在具有丰富计算资源的高级服务器上时,通过更多的并行化可以减少预处理的时间开销。
5. 结论
本文提出了一种基于多模态特征深度融合的安卓恶意软件检测方法。该方法的主要特点如下:
创新点
-
构建新型调用图
- 构建了名为类集调用图(class-set call graph)的新型调用图
- 使用类集代码的 LSI 特征作为节点特征
- 通过图注意力网络提取显著区域特征
- 有效整合了安卓应用的语义特征和结构特征
-
动态自适应节点合并方法
- 增强每个节点的语义信息
- 减少第三方库的影响
- 在尽可能保留原始信息的同时减少调用图的规模
-
多特征融合点网络
- 建立了多特征融合点网络
- 融合图特征和权限特征
- 对安卓应用进行二分类
实验结果
- 基于多个数据集进行实验
- 准确率达到97.28%-99.54%
- 优于现有最先进的方法
未来工作方向
-
效率提升
- 进一步研究预处理并行化方法
- 提高检测效率
-
对抗混淆
- 考虑应对混淆技术的检测方案
-
特定类型恶意软件
- 热加载模块检测
- 钓鱼检测
原文谷歌翻译
本文提出了一种基于多模态特征深度融合的Android恶意软件检测方法。该方法构造了一种新类型的调用图,名为类集调用图。使用类集代码的LSI特征作为节点特征,并使用图注意网络提取显着区域特征。因此,该方法有效地融合了Android应用程序的语义特征和结构特征。为了增强每个节点的语义信息,提出了一种动态自适应节点合并方法。这种方式还可以在尽可能保留原始信息的同时,减少第三方库的影响,缩小调用图的规模。最后建立多特征融合点网络;它融合了图特征和权限特征来为Android应用程序执行二元分类。我们基于多个数据集进行了实验,结果表明我们的方法达到了 97.28-99.54% 的准确率,高于最先进的方法。
在我们未来的工作中,我们将进一步研究预处理并行化方法以提高我们方法的检测效率,并考虑一些检测方案来处理混淆技术。此外,我们将更加关注特定类型的恶意软件,例如热加载模块检测和网络钓鱼检测。
CRediT 作者贡献声明 Shaojie Chen:方法论、软件、验证、写作 - 初稿、编辑。博朗:概念化、监督、写作——审查和编辑。刘宏宇:调查、写作审查和编辑、数据管理。陈一凯:调查、写作、评论和编辑。宋育才:数据管理、软件、验证。竞争利益声明 作者声明,提交本稿件不存在利益冲突,所有作者均批准稿件发表。所描述的工作是以前未发表过的原创研究,并且没有考虑在其他地方发表全部或部分内容。列出的所有作者均已批准所附的手稿。数据可用性 数据将根据要求提供。致谢这项工作得到了软件开发环境国家重点实验室的资助[资助号SKLSDE-2020ZX-02]。所有作者阅读并认可的终稿。
参考文献